Screenshots
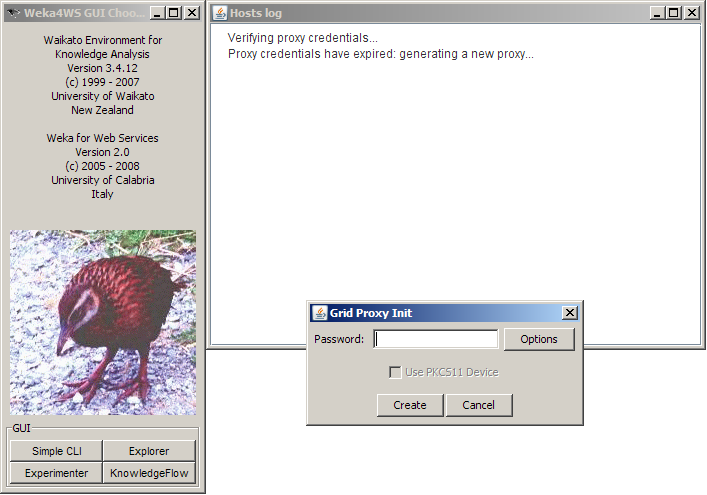
The Gui Chooser (left side), used to launch Weka’s four graphical environments. The hosts list checking window (top right side), automatically loaded at startup to check whether on every host:
- the Globus Container is running and accessible;
- the GridFTP Server is running and accessible;
- the requesting user has an account on the host;
- the Weka4WS service is deployed and accessible;
- the Weka4WS client and service versions are the same.
The Grid Proxy Initialization window (middle right side), automatically loaded at startup if the user credentials are not available or have expired.
~
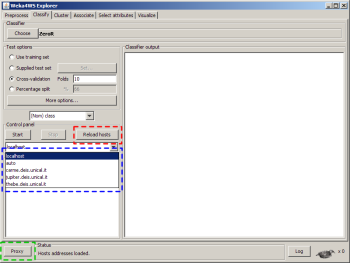
The Weka4WS Explorer component with the modified parts highlighted. Through a drop down menu (in blue) it is possible to choose on which remote host we want the data mining task to be computed; the Reload hosts button (in red) brings up the hosts list checking window (described above); the Proxy button (in green) brings up the Grid Proxy Initialization window (described above).
~
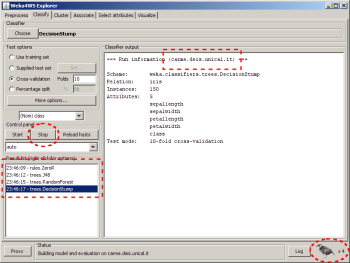
The Weka4WS Explorer showing multiple tasks executed concurrently on some remote hosts. The number of running tasks is displayed on the right-lower corner. At the top of the output panel is displayed the host name where the task is being computed. At any time it is possible to stop a remote task by selecting the task from the ‘Result list’ (at the left-lower corner) and pressing the ‘Stop’ button.
~
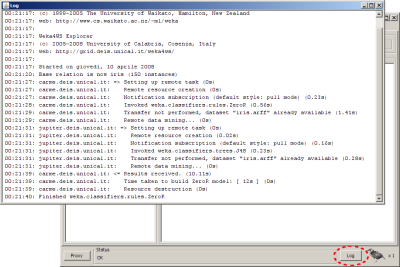
With a very detailed logging it’s possible to follow the remote computations on their very single steps, as well as to know their execution times.
~
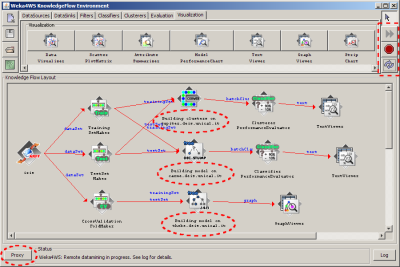
The KnowledgeFlow component with the modified parts highlighted. Three buttons (in the upper right corner) are used, from top to bottom, to start all the tasks, to stop them and the last one is to bring up the hosts list checking window (described earlier). During the computation the label below each algorithm node displays the location address upon where the computation is taking place. The Proxy button (in the lower left corner) brings up the Grid Proxy Initialization window (described earlier).
~
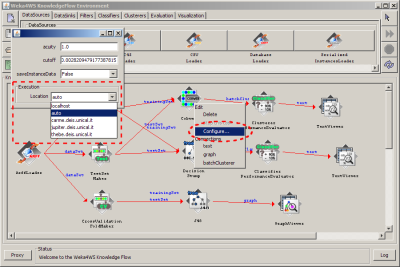
The choice of the location where to run a certain algorithm is made into the configuration panel of each algorithm, accessible right clicking on the algorithm icon and choosing Configure: through a drop down menu it is possible to choose on which remote host we want the selected data mining task to be computed.
~
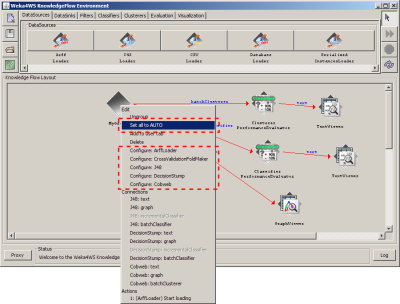
For complex workflows the grouping feature in sub-flows of the KnowledgeFlow is useful to easily and quickly set the computing locations of the algorithms by either setting to Auto all the computing locations of the algorithms belonging to the sub-flow, or choosing the specific location of each algorithm by accessing the relative configuration listed in the menu.